En el segundo seminario de la asignatura nos centramos en la pestaña "Analiza datos" de Epi Info.
Para realizar el análisis pinchamos en el "abrir", que se encuentra en el apartado de "datos" a la izquierda de la imagen, y seleccionamos la vista "ViewOswego"
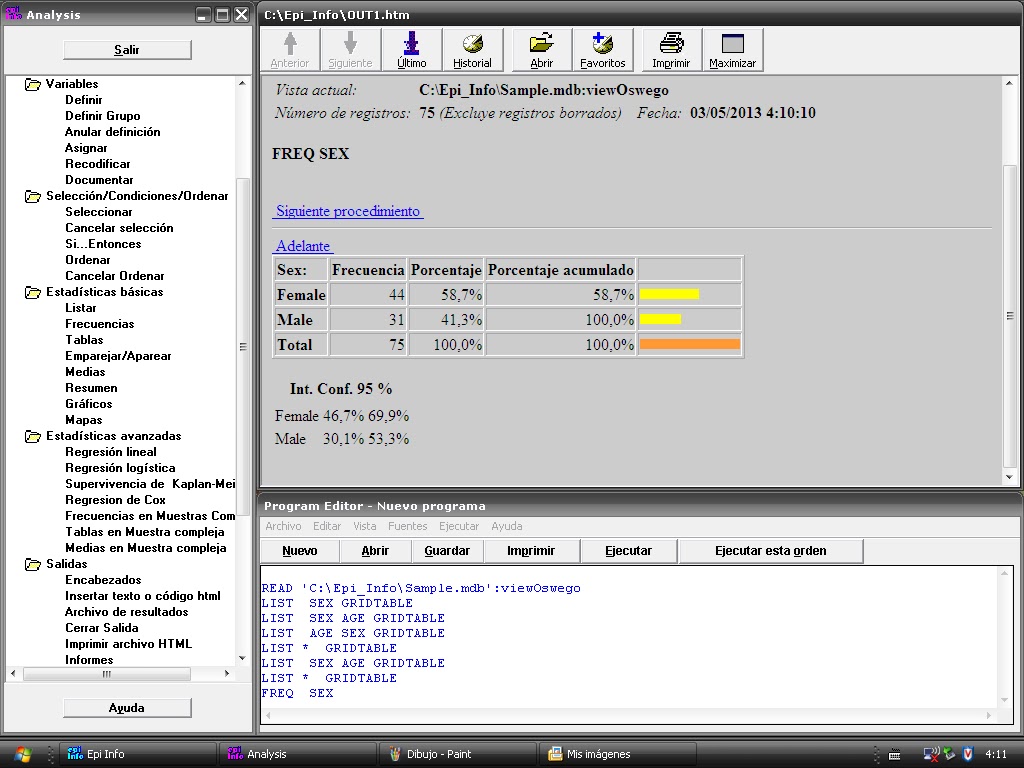
Una vez hecho esto, nos sale que el nº de registros es 75, es decir, que tenemos 75 personas registradas que completaron el cuestionario realizado en el seminario anterior.
El paso siguiente sería relacionar las edades de las personas con el sexo. Para ello pichamos en "estadística básica" y entramos en "listar". Si marcamos "todo menos" y no seleccionamos nada, nos saldría todo el listado.
Para hacer una tabla de frecuencias le damos al apartado de "frecuencias" y ponemos, en este caso, la palabra "SEX" en "frecuencia de" y hacemos otra con la palabra "ILL".
En este caso el intervalo de confianza es del 95%. Este intervalo es un estimador poblacional y si es muy amplio nos indica que tenemos una muestra muy dispersa.
A continuación procedemos a agrupar las variable para convertir la variable cuantitativa en cualitativa. Tomamos 3 intervalos según el grupo de edad. Pinchamos en "definir" en el apartado de "variables" y nos sale el siguiente cuadro, que completaremos.
Seguidamente le daremos a "recodificar" y crearemos los grupos de edad correspondientes:
Menores de edad: 0-17
Adultos: 18-65
Ancianos: 66-120
Realizamos una tabla de frecuencia con estos datos:
Seguidamente entramos en el apartado de "gráficos", elegimos "sexo" como variable principal para hacer un gráfico de sectores en el que se vea reflejado la cantidad de hombres y mujeres (imagen 1) y hacemos un histograma para ver la variable "edad" (imagen 2).
Imagen 1.
Imagen 2.
El siguiente paso sería realizar un gráfico (imagen 3) relacionando los diferentes alimentos consumidos en la fiesta del caso que estamos analizando y la cantidad de personas los consumieron o no (contestaron "sí" o "no").
Imagen 3.
Es conveniente saber que las imágenes de los gráficos que hagamos con este programa se guardan automáticamente en el ordenador.
Pienso que lo bueno de este tipo de seminarios es que nos servirán mucho (o eso espero) para el trabajo de investigación que seguimos realizando.











 3 veces la desviación típica (S)= 99,73% de las observaciones.
3 veces la desviación típica (S)= 99,73% de las observaciones.

























{kind=link}
{kind=link}